
Mathematical modelling identify factors that contribute to cancer risk.
Epidemiologists have long observed that the life-time probability of cancer varies greatly among different organs from which cancers originate. A new study in Science and a Perspective article shed a new light on this problem.
According to the prevalent hypothesis, cancer occurs when alterations of the genetic material cause cells to proliferate in an uncontrolled way. These alterations arise due to “intrinsic” processes such as random errors during DNA replication, and “extrinsic” factors such as chemical mutagens and ionizing radiation. A recent Science paper attempted to estimate contributions from these different processes. Using epidemiological data from 69 countries, researchers Cristian Tomasetti, Lu Li, and Bert Vogelstein (Baltimore) found a strong correlation between the logarithm of the life-time number of cellular divisions in a given tissue and the logarithm of cancer incidence rate in the same tissue. They also combined data from cancer genome sequencing projects and epidemiological studies and showed that mutations due to replication errors account for 2/3 of all mutations found in cancer.
In the Perspective article, Martin Nowak (Harvard) and Bartlomiej Waclaw (Edinburgh) show that although these results are very interesting, there is a huge gap in our understanding what actually contributes to cancer risk.
“Given what we know about cancer biology, the correlation between the risk of getting cancer and the number of stem cell divisions is not that surprising” - says B. Waclaw – “What is more surprising is that cancer risk increases slower than linearly with the number of cell divisions”.
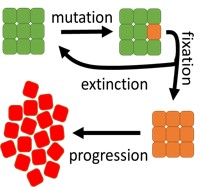
To find out what a theoretical relationship between cancer risk and cellular divisions should be, researchers considered a mathematical model (see the picture). The model shows that cancer risk is the product of the probabilities of cancer initiation and progression. Cells in normal tissues are often divided into “compartments” of size a few to a hundred cells. Initiation requires a single cell to become “neoplastic”: to acquire a mutation that causes the cell to produce more offspring than normal cells do. The population of this neoplastic cell must then take over the entire compartment before it can spread to surrounding tissues. This process, called “fixation”, is stochastic and sometimes neoplastic cells die out. Depending on the number of mutations required to produce the first neoplastic cell, mathematical modelling predicts a linear or faster-than-linear relationship between risk R and the number of cell divisions D, R ~ D^a, where a is larger or equal to 1. However, epidemiological data shows that the risk is a sublinear function of D, and a is approximately 0.5.
The discrepancy between the model and reality means that there must be additional factors that lower cancer initiation rate in tissues with larger number of divisions. For example, additional “checkpoints” may be present in such tissues that need to be deactivated to enable cancer progression. Tissue geometry may also play a role in reducing the initiation rate in tissues with higher proliferative potential. Researchers are now working on mathematical models that would take these factors into account.